
Aprendizagem Supervisionada: O pilar da Inteligência Artificial que ensina máquinas através de exemplos
A Aprendizagem Supervisionada consolidou-se como a técnica mais utilizada no desenvolvimento de sistemas inteligentes modernos, impactando desde a organização das suas pastas de e-mail até a aprovação de crédito bancário.
Neste artigo, explicamos como esse conceito funciona, as etapas para sua implementação e por que ele é fundamental para o avanço da tecnologia atual.
O que é Aprendizagem Supervisionada?
A Aprendizagem Supervisionada é uma subcategoria da Inteligência Artificial onde um modelo é treinado usando um conjunto de dados previamente “rotulados”. Na prática, isso significa que fornecemos à máquina o problema e a resposta correta para que ela aprenda a identificar padrões.
Imagine que você está ensinando uma criança a distinguir frutas. Você mostra uma maçã e diz: “Isso é uma maçã”. Depois mostra uma banana e diz: “Isso é uma banana”. Após repetir esse processo várias vezes com exemplos diferentes, a criança será capaz de identificar uma fruta que nunca viu antes com base no que aprendeu.
Termo técnico: Dados Rotulados (Labeled Data)
São informações que já possuem uma etiqueta ou categoria definida.
Exemplo: Em um banco de dados de e-mails, o “rótulo” seria a marcação manual indicando se aquela mensagem é “Spam” ou “Importante”.
Como funciona a implementação na prática
Implementar um sistema de Aprendizagem Supervisionada exige um fluxo de trabalho estruturado, que vai da coleta de dados à validação do modelo.
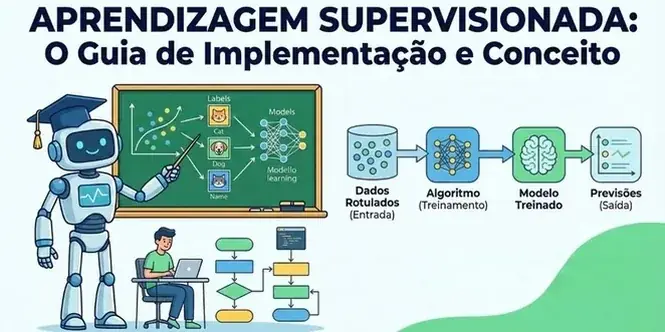
1. Coleta e Preparação de Dados
O sucesso do modelo depende da qualidade dos dados. Se os dados estiverem incorretos ou incompletos, a máquina aprenderá padrões errados. Nesta fase, os desenvolvedores limpam e organizam as informações.
2. Escolha do Algoritmo
Dependendo do objetivo, escolhe-se um algoritmo específico. Existem dois caminhos principais:
-
Classificação: Usado para separar coisas em categorias.
(Exemplo: Identificar se uma transação bancária é “fraude” ou “legítima”). -
Regressão: Usado para prever valores numéricos contínuos.
(Exemplo: Prever o preço de um imóvel com base no tamanho e localização).
3. Treinamento
Aqui, o conjunto de dados é dividido. Uma parte (geralmente 80%) é entregue ao algoritmo para que ele estude as relações entre as características (inputs) e os resultados (outputs).
4. Teste e Validação
A parte restante dos dados (20%) é usada para testar o modelo. Como o sistema já conhece as respostas corretas desses dados, ele pode medir o quão preciso o algoritmo se tornou.
Os desafios técnicos: O equilíbrio da aprendizagem
Um dos maiores desafios na implementação da Aprendizagem Supervisionada é evitar erros de ajuste do modelo.
-
Overfitting (Sobreajuste):
Ocorre quando o modelo “decora” os exemplos de treino de forma tão específica que não consegue lidar com dados novos. É como um aluno que decora as questões de um simulado, mas erra tudo na prova real porque as perguntas mudaram um pouco. -
Underfitting (Subajuste):
Ocorre quando o modelo é simples demais e não consegue nem aprender os padrões básicos dos dados.
Impacto prático no cotidiano do usuário
A Aprendizagem Supervisionada não é apenas uma teoria de programação; ela move serviços que usamos diariamente:
-
Filtros de Spam:
Seu Gmail ou Outlook utiliza essa técnica para reconhecer palavras-chave e comportamentos típicos de mensagens indesejadas. -
Diagnóstico Médico:
Algoritmos analisam milhares de exames de imagem rotulados por médicos para identificar tumores precocemente com alta precisão. -
Reconhecimento de Voz:
Assistentes como Alexa e Siri aprendem a associar ondas sonoras a palavras específicas através de treinamento supervisionado.
Vantagens e Limitações
Como toda tecnologia, a Aprendizagem Supervisionada possui pontos fortes e fracos que devem ser considerados antes de sua aplicação.
Principais Vantagens:
-
Clareza nos Objetivos:
Como o modelo sabe exatamente o que deve buscar (baseado nos rótulos), é mais fácil medir seu desempenho e realizar ajustes precisos. -
Alta Precisão:
Quando treinados com bons dados, esses algoritmos atingem níveis de acerto superiores aos humanos em tarefas específicas, como reconhecimento de padrões em imagens médicas. -
Previsibilidade:
Diferente de outros métodos, o comportamento do modelo tende a ser mais consistente, pois é guiado por regras aprendidas de exemplos concretos.
Limitações Importantes:
-
Dependência de Dados:
O sistema é tão bom quanto os dados que recebe. Se os dados de treino forem tendenciosos ou incompletos, o modelo replicará esses erros. -
Custo de Rotulagem:
Preparar os dados exige muito trabalho manual. Alguém precisa classificar milhares de exemplos antes que a máquina possa começar a aprender. -
Dificuldade com Contradições:
O algoritmo pode se confundir facilmente se os exemplos rotulados contiverem informações contraditórias ou ambíguas.
Disponibilidade e o futuro da tecnologia
Atualmente, implementar Aprendizagem Supervisionada tornou-se acessível para empresas de todos os tamanhos. Ferramentas de código aberto e bibliotecas como Scikit-learn, TensorFlow e PyTorch permitem que desenvolvedores criem soluções robustas sem começar do zero.
A tendência futura aponta para modelos híbridos. Embora a supervisão humana ainda seja essencial para garantir a precisão e a ética nos dados, estamos caminhando para sistemas que exigem cada vez menos intervenção manual para rotular grandes volumes de informação.
A Aprendizagem Supervisionada continuará sendo a base para inovações em carros autônomos e personalização extrema em plataformas de streaming, tornando a interação entre humanos e máquinas cada vez mais fluida e inteligente.